本文共 2168 字,大约阅读时间需要 7 分钟。
背景
我们目前接触过的绝大部分迁移学习问题情景都是:源域和目标域的特征空间与类别空间一致,只是数据的分布不一致,如何进行迁移。也就是说,源域和目标域要是几类,都是几类。
但是这种情况显然具有很大的限制性:在真实应用中,我们往往不知道目标域的类别,更无法获知它是否和源域的类别完全一样。这就极大地限制了它的应用。
迁移学习的目标就是利用大量有标注的源域数据来对目标域数据进行建模。如果我们假设已有的源域数据很丰富,它本身就包含了目标域的类别,那么问题会不会看起来更具一般性?
形式化来讲,我们用 Ys 和 Yt 分别表示源域和目标域的类别空间,那么部分迁移学习就是Y ⊃ Yt。这种情况比通常意义下的迁移学习更有挑战性。
论文动机
作者的 motivation 很直观:如果在源域类别比目标域多的情况下无法直接进行迁移,那我们就先选择出源域中与目标域那部分类别最接近的样本,给它们赋予高权重,然后再进行迁移。
基于这个想法,作者设计了一个两阶段的深度对抗网络。我们都知道对抗网络主要由特征提取器(feature extractor)和领域分类器(domain classifier)组成。特征提取器用于进取样本的公共特征,领域分类器用于判别两个领域是否相似。
已有工作通常会对源域和目标域采用一个公共的特征提取器。但是在部分迁移学习中,源域和目标域的类别往往不同,因此作者提出对它们分别采用不同的特征提取器进行。这样做还有一个好处就是,不同的特征提取器可以针对各自的 domain 学习到各自的表征性特征。
在学习时,固定源域的特征提取器不变,只学习目标域的特征,这更符合原始 GAN 的理论。
方法
作者提出了一个深度加权对抗网络(Importance Weighted Adversarial Nets)。这个网络的示意图如下图所示。
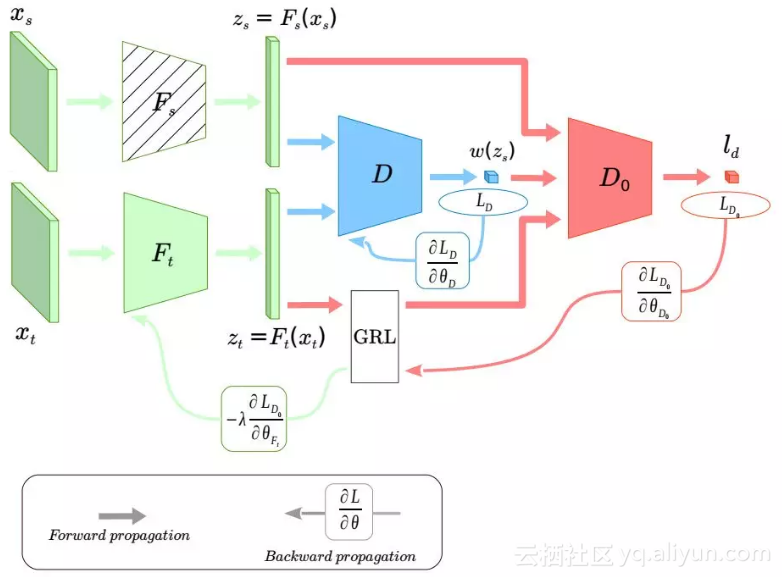
网络的主要部分为:分别作用于源域和目标域的两个特征提取器(分别叫做 Fs 和 Ft),以及两个领域分类器(分别叫做 D 和 D0)。
第一个领域分类器用来筛选出源域中与目标域相似的那部分样本(或者源域中与目标领域共享的那部分类别),第二个领域分类器进行正常的 Domain Adaptation。
相应地,方法主要分为两个部分:1)筛选出源域中与目标域属于相同类别的样本,2)综合学习。
样本筛选
此部分是该论文的核心创新点。主要思路是,由 Fs 和 Ft 产生的源域和目标域特征 Zs 和 Zt,通过一个领域分类器 D,判别样本是来自于源域还是目标域。
这个 D 是一个二类分类器,如果 D=1,表示样本来自源域;否则,样本则来自目标域。那么,如何才能知道样本是否属于源域和目标域的公共类别,而不是特异于源域的类别(作者叫它们 outlier)?
如果 D(z)≈1,那么就表示 z 这个样本是来自于源域。更进一步分析,为什么这部分样本只是来自源域?那是因为这部分样本是源域独有的。否则的话,它就同样来自目标域了。
从另一个角度说,如果 D(z)≈0,则表示这部分样本来自目标域。同时,也表示它可能来自源域中与目标领域共享的类别。因为两部分的类别是共享的。
这个简单而直观的道理指导着我们设计不同的权重。我们的目标是,对于筛选出的那部分与目标域属于相同类别的源域样本,给它们赋予大权重;另一部分源域特有的样本,权重调小。该权重可以被表示为:
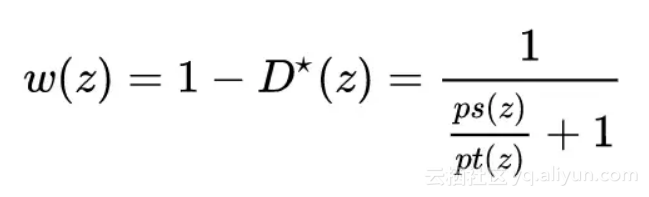
这里的 D⋆(z) 表示的是领域分类器 D 的最优值,它可以通过求导得出:
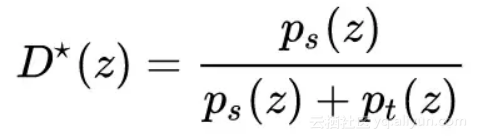
从这个式子可以看出,如果 D⋆(z) 值较大,则表示样本更可能是 outlier,那么权重值就会变小;反之,如果 D⋆(z) 值较小,则表示样本更可能是源域和目标域共同部分,那么权重值就会变大。这个方法很好地对源域和目标域中的共同类别的样本完成了筛选工作。
作者还对源域部分的权重进行了归一化,以更加明确样本的从属关系。加入权重以后,优化目标变成了:
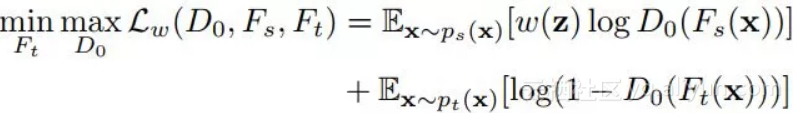
下一步工作是处理领域分类器 D0。D0 也可以以同样的求导方式得到。
综合学习
综合学习之前,作者还加了一个熵最小化项用于对目标域的样本属性进行约束,这也是比较常见的做法。熵最小化可以被表示为:
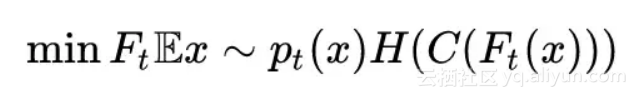
其中的 H(⋅) 就是熵的表达形式。C(⋅) 是分类器。现在,总的学习目标就是:
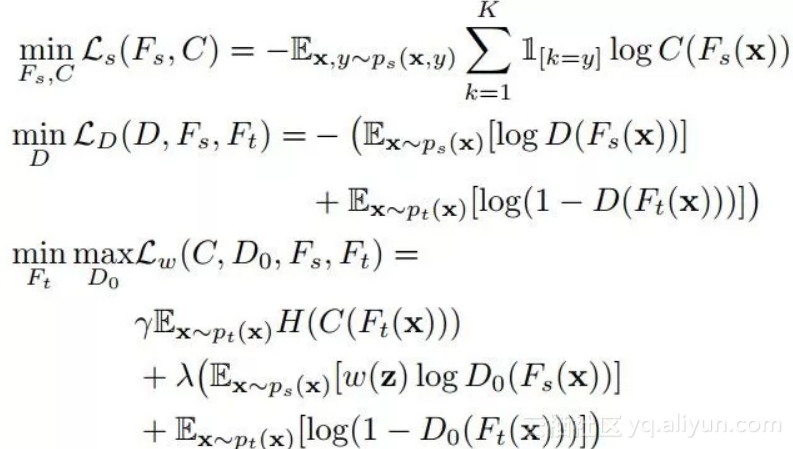
实验
部分迁移学习实验主要在传统的 Office-Caltech 以及 Office-31 上做。不过实验任务与之前的迁移学习有所不同:源域的类别比目标域多。
作者和一些最新的迁移学习方法进行了对比,表明了所提方法的优势。
作者还特别做了一个实验:当目标域的类别个数逐渐变多时,精度如何变化?结论是,随着目标域类别个数的减少,精度逐渐增加。这表明知识在进行迁移时,源域知识越多,通过筛选,对目标越有效。
具体实验设定、结果、以及其他的可视化结果可以参照原文。
总结
本文核心创新点是,从任务出发,直观地构造出两阶段式对抗网络,对源域中与目标域共享的类别样本进行有效筛选。
另一个与已有工作不同的地方是,作者分别对源域和目标域采用了不同的特征提取器。其实这一点与作者发表在 CVPR-17 的 JGSA [1] 方法很像。可以参考学习。
原文发布时间为:2018-04-12
本文作者:王晋东
本文来自云栖社区合作伙伴“”,了解相关信息可以关注“”。
转载地址:http://rlwvx.baihongyu.com/